Cuantificación de neuronas C-Fos positivas en secciones de cerebro de ratón usando la tecnología deep learning TruAI™
Avances en inteligencia artificial (IA): del machine learning al deep learning
El término "inteligencia artificial" se ha asociado durante mucho tiempo a la idea de las tecnologías futuristas que pueden ampliar considerablemente las capacidades de investigación y los avances tecnológicos. La inteligencia artificial ha existido desde los años 50 y se ha utilizado de varias formas desde su creación. En términos generales, la inteligencia artificial (IA) hace referencia a cualquier técnica que permita que las máquinas imiten la inteligencia humana. La IA puede clasificarse posteriormente en una técnica más avanzada conocida como "machine learning", que emplea métodos estadísticos para que las máquinas aprendan tareas a partir de datos sin una programación explícita. La forma más avanzada de IA recibe el nombre de "deep learning". Esta técnica utiliza redes neuronales que contienen muchas capas que pueden aprender las representaciones y las tareas directamente de conjuntos de datos complejos. El deep learning ahora es tan potente que algunas veces puede llegar a superar la precisión de los humanos a la hora de clasificar las imágenes.
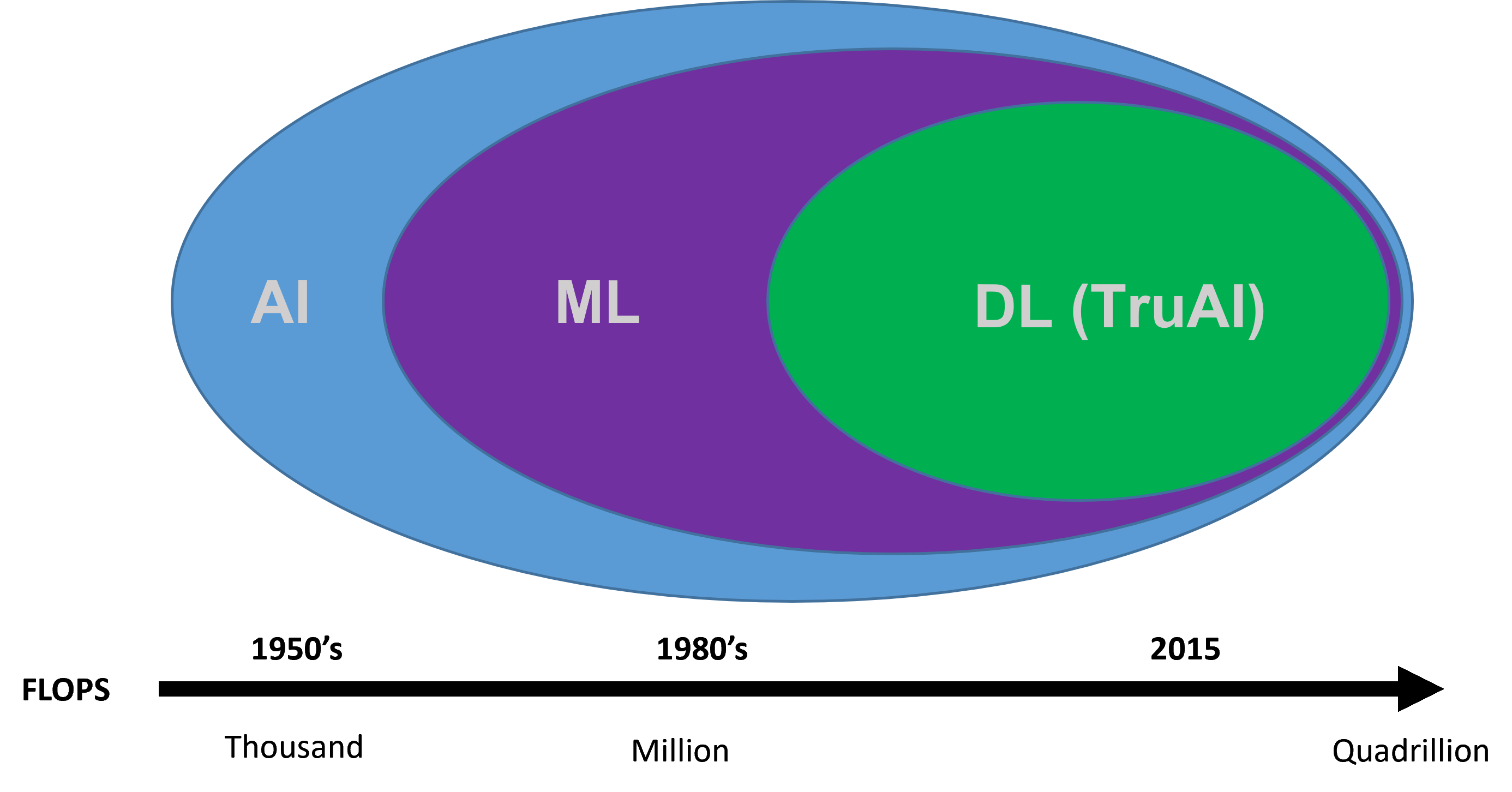
Figura 1. Cronograma del desarrollo de inteligencia artificial.
Aplicación de la IA deep learning a la microscopía
La IA, y más específicamente el deep learning, puede aplicarse fácilmente para que los investigadores puedan producir un análisis sólido de sus datos con mayor precisión y en menos tiempo. Las redes neuronales de la tecnología TruAI™ de Olympus son las redes neuronales de convolución que proporcionan la tecnología de segmentación de objetos ofreciendo una alta adaptabilidad para analizar conjuntos de datos complejos o desafiantes. Estas redes pueden evaluar los diversos tipos de evidencias o datos de entrada y tomar decisiones sobre los datos, una tarea que normalmente está sometida a la parcialidad humana subyacente cuando se realiza manualmente. Esta nota de aplicación demuestra un ejemplo real de cómo la tecnología TruAI beneficia el análisis de segmentación automático de neuronas c-Fos positivas en el cerebro del ratón, especialmente si lo comparamos con herramientas de IA menos avanzadas.
Resumen del experimento - Evaluación de las consecuencias sistémicas de la neurogénesis interrumpida
En este experimento, el investigador tuvo que cuantificar la expresión de las neuronas c-Fos positivas en la región del hipocampo del cerebro (el área del cerebro responsable de la memoria y el aprendizaje) para poder evaluar las consecuencias sistémicas de la neurogénesis interrumpida. C-Fos es un protooncogen cuya expresión puede usarse como marcador para la actividad neuronal. Los métodos de segmentación morfométricos/de intensidad convencionales no son efectivos ni eficientes para generar conjuntos de datos sólidos, ya que los conjuntos de datos muestran niveles variables de antecedentes y niveles de intensidad objetivo que complican los intentos de realizar análisis manuales (Figura 2). Además, requieren arduas auditorías de los resultados para eliminar los falsos positivos.
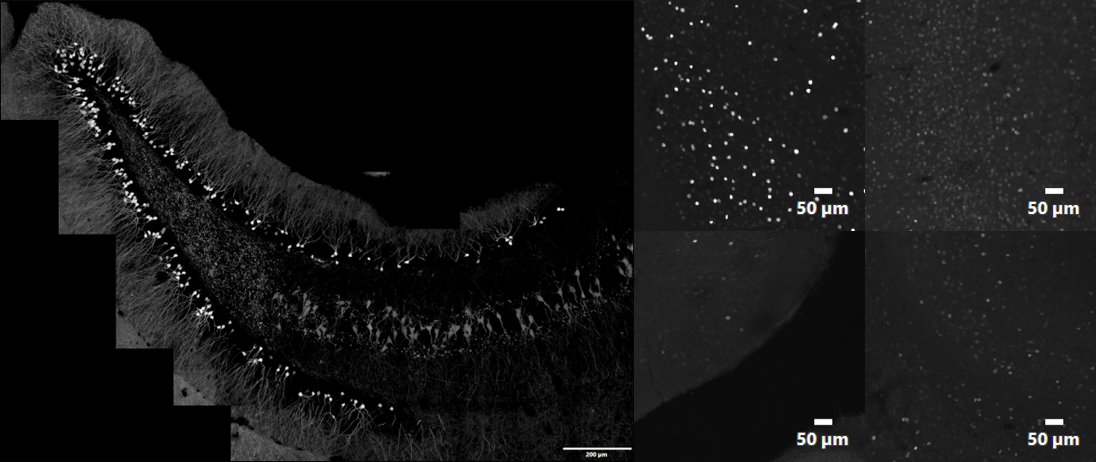
Figura 2. Ejemplo de tipo de conjunto de datos que requiere análisis de segmentación: imagen combinada de toda la región del hipocampo de un ratón transgénico expresando tdTomato bajo un impulsor c-Fos (izquierda) e imágenes individuales que ilustran la variabilidad de la señal c-Fos, así como los niveles de fondo de la imagen dentro de la imagen combinada (derecha). Imágenes de pila Z 1k × 1k adquiridas con SAPO 10X y zoom 2x a 1 AU.
Entrenamiento de la red neuronal TruAI para identificar la expresión c-Fos positiva
El protocolo de entrenamiento de red neuronal (NN) de la Tecnología TruAI requiere un conjunto de datos de "entrenamiento" que define una base verídica para realizar análisis e identificaciones posteriores. Esta base verídica puede basarse en la anotación del usuario de los datos sin procesar o puede generarse automáticamente usando la función de segmentación y definición de umbral morfométrico/intensidad del software cellSens. A partir de esta entrada de datos inicial, el TruAI NN aprende y utiliza los conjuntos de datos experimentales durante el periodo de entrenamiento iterativo eliminando la necesidad de que el usuario introduzca más datos. Esta definición de la base verídica permite a TruAI NN decidir qué es real (objetivo) y qué no lo es (no objetivo). En este experimento, se utilizaron ocho conjuntos de datos con diversos niveles de expresión c-Fos para entrenar al TruAI NN (Figura 3). Partiendo de estos conjuntos de datos, el TruAI NN realizó un entrenamiento exhaustivo con 40.000 iteraciones para generar el NN que se usaría para analizar las imágenes posteriores. Durante el proceso de entrenamiento iterativo, se monitorizó una imagen de validación, seleccionada del conjunto de entrenamiento inicial, y se utilizó para realizar la comparación.
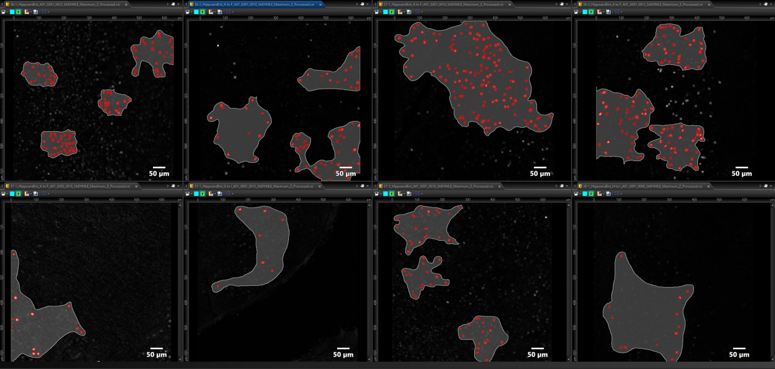
Figura 3. Entrenamiento de conjuntos de datos usados para la generación de la red neuronal (NN) TruAI: se utilizaron ocho conjuntos de datos con distintos niveles de expresión para delinear el objeto (rojo) vs. el fondo (gris).
Utilización de la red neuronal TruAI para análisis de conjuntos de datos en lotes
Después de generar la NN TruAI entrenada, se utilizó para el procesamiento de lotes y el análisis de los conjuntos de datos restantes. La Figura 4 muestra el mapa de probabilidad y el análisis de segmentación posterior que se realizó usando la NN TruAI resultante. La NN TruAI permitió segmentar el conjunto de datos partiendo de la capa de probabilidad y posteriormente se aplicaron los algoritmos de clasificación y división automática del software cellSens para generar las métricas cuantitativas de las células c-Fos positivas basadas en intensidad media, intensidad total y área. La función Macro Manager del software cellSens permitió procesar los conjuntos de datos restantes en lotes.
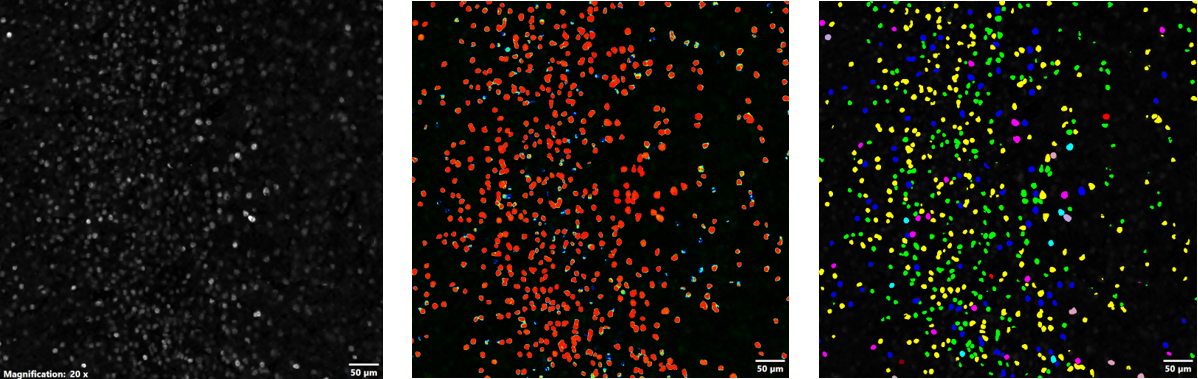
Figura 4. Utilización de la NN para segmentación y definición de umbral: Imagen adquirida con el microscopio FV3000 de células c-Fos positivas (izquierda), mapa de probabilidad de células c-Fos positivas generado por el NN (medio) y segmentación de células c-Fos positivas basada en la capa de probabilidad (derecha); los datos se dividieron automáticamente en función de la intensidad media, la intensidad total y el área.
Como hemos mencionado anteriormente, el beneficio de usar la tecnología deep learning es que permite realizar una identificación de objetos más sólida que otros programas de IA. En este experimento, la tecnología deep learning TruAI empleó ocho conjuntos de datos que se sometieron a cerca de 40.000 iteraciones para producir un NN para analizar posteriormente los conjuntos de datos restantes. La ventaja de usar estos protocolos de entrenamiento tan robustos es que permite a la NN ser más precisa a la hora de identificar los objetos cuando la imagen no es excelente, por ejemplo cuando el fondo es alto y la expresión del objetivo es baja. Esta ventaja se ejemplifica en la Figura 5, donde se compara el rendimiento de la NN TruAI con una red entrenada con menos rigor que estaba basada únicamente en un conjunto de datos de entrenamiento. A niveles de expresión superiores, los dos algoritmos identificaron el mismo número de células. Sin embargo, a niveles muy bajos de expresión, la red entrenada con menos rigor sobreestimó el número de células c-Fos positivas en casi el doble, lo que habría afectado considerablemente a las conclusiones extraídas del experimento. La tecnología deep learning TruAI pudo solventar con éxito los niveles variables de intensidad c-Fos y de fondo para ofrecer resultados más precisos sin tener que realizar auditorías manuales de los datos para eliminar falsos positivos.
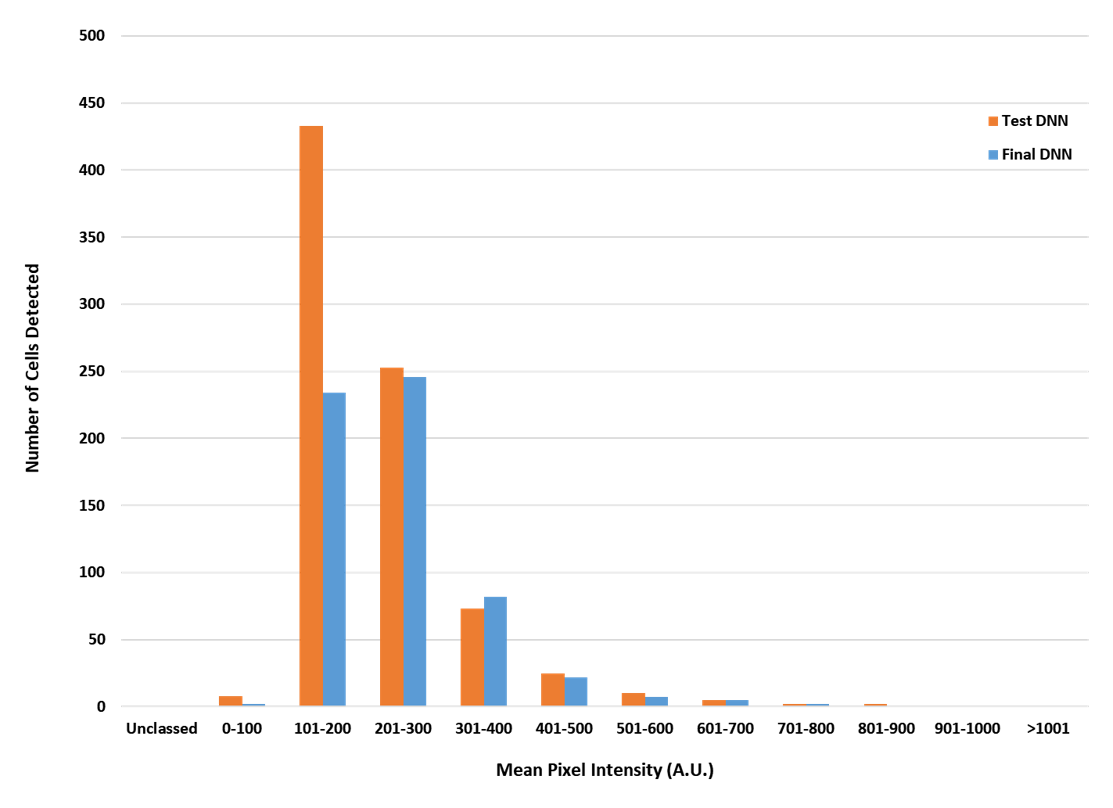
Figura 5. Comparación de índices de identificación c-Fos-positivo de una red con menos entrenamiento vs. la red neuronal TruAI; las barras de color naranja representan la red entrenada con menor rigor derivada de un conjunto de datos único usando 2000 iteraciones, y las barras de color azul muestran los resultados de la NN TruAI derivados de los ocho conjuntos de datos usando 40.000 iteraciones.
Comentario del investigador Dr. Jonathan Epp, Universidad de Calgary
 | Hay una serie de factores que afectan a la forma de ver los enfoques de IA y sus beneficios en la investigación científica. Un aspecto importante que suelo repetir al hablar de este tipo de sistemas es que nos ayudan a eliminar la parcialidad del experimentador al cuantificar las imágenes, ya que, aunque no podemos obviar las condiciones del experimento, no estamos decidiendo sobre el tejido experimental real y no es una célula etiquetada. Dejando a un lado la parcialidad, también ayuda a reducir la variabilidad entre los diversos experimentadores y experimentos en el laboratorio y, en última instancia, aumenta la reproducibilidad de nuestros datos. Creo que este tipo de enfoque es una forma importante de ayudar a garantizar que estamos tomando los pasos adecuados para solventar los problemas de reproducibilidad tan frecuentes en la actualidad. |
Reconocimientos
Esta nota de aplicación ha sido redactada con la ayuda de los siguientes investigadores:
Dr. Jonathan Epp, Universidad de Calgary
Productos usados para esta aplicación
Sorry, this page is not
available in your country.